

Across my real-estate portfolio, user-submitted listings arrive incomplete, inconsistent and occasionally spammy. Reviewing them by hand does not scale. So I built an agentic content pipeline on top of Claude Code skills and my own MCP server. The result reviews, corrects and conditionally publishes listings across multiple sites — with humans setting the rules and the agent doing the work. Here is how it is structured.
This is a hands-on field report, not a theoretical design: everything below comes from actually running this pipeline on my own real-estate sites, where a growing backlog of user-submitted listings made manual review impossible to sustain. I’m sharing the structure, the guardrails and the trade-offs that made me comfortable letting an agent correct and publish live content with limited supervision — in case it helps anyone building something similar.
Composition over one giant prompt
The instinct with agents is to write one enormous instruction and hope. The better pattern, I found, is the same one we use in software: small units that compose. The pipeline is three layers of skills:
- A single-listing skill reviews one listing end to end: it checks the minimum required input, filters spam, fixes the title, description, location and price, renames the main image for SEO, fills in the SEO metadata, then runs an audit.
- A site-level skill discovers every pending listing on one site and loops the single-listing skill over each, aggregating a report.
- A multi-site skill fans out across all the relevant sites in a defined order, then aggregates a cross-site report.
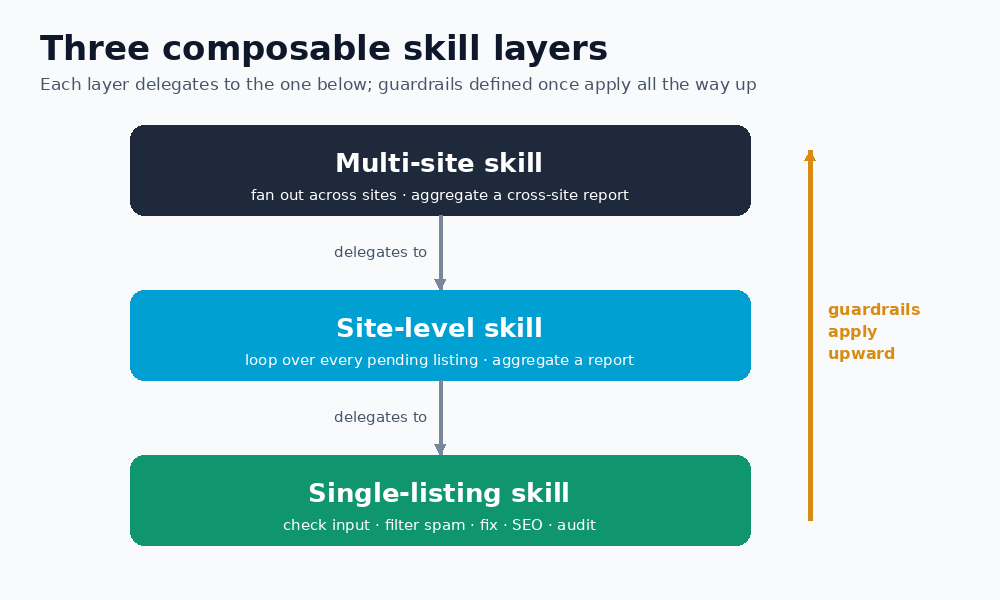
Each layer delegates entirely to the one below it. The guardrails defined at the bottom apply automatically all the way up — there is no duplicated logic to drift out of sync.
Guardrails are the whole game
An agent editing live content is only as trustworthy as the rules constraining it. The pipeline encodes several non-negotiables:
- Status filter: only listings in a pending state are ever touched.
- Minimum input: a listing missing essentials (type, status, locality) is flagged for a human, not invented.
- Spam detection: off-topic or fraudulent submissions are set aside, never corrected and published.
- Duplicate detection: near-identical listings in a batch are caught and drafted rather than republished.
- Formatting conventions: domain rules — like how numbers and prices are displayed — are enforced consistently.
These are not suggestions in a prompt; they are explicit gates the skill must pass at each step.
The audit gate: the line between draft and publish
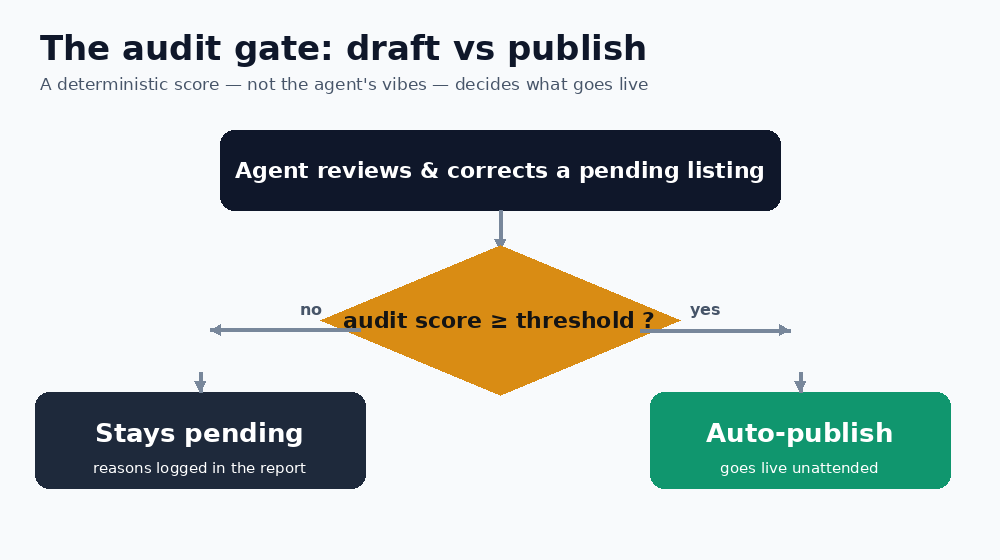
The single most important design choice was making publication conditional on a measurable score. After the agent finishes editing a listing, an audit tool scores it against schema rules: required fields present, meta correctly typed, taxonomies assigned, images with alt text, SEO title and description within length limits.
If the score clears the threshold, the listing auto-publishes. If not, it stays pending with the reasons recorded in the report. The agent never decides “this looks good enough” on vibes — a deterministic check does. That is what makes unattended publishing acceptable.
Reports as the human interface
Every run writes a structured report: how many listings were detected, how many were corrected, published, kept pending, flagged as insufficient input, spam or duplicates, and any errors. The reports are persisted outside the repo so I can review what the agent did after the fact. Error tolerance is built in — one bad listing logs its failure and the loop moves on instead of collapsing.
Lessons for building your own
- Decompose the workflow into skills that mirror your real process; let higher levels delegate, not re-implement.
- Encode guardrails as gates, not polite requests.
- Gate side effects on a deterministic check — a score, a lint, a test — so the agent’s judgement is bounded.
- Make the output auditable. A clear report is what lets you trust automation you did not personally supervise.
Agentic does not mean unsupervised in spirit. It means the human moves up a level — from doing each task to designing the rules, the gates and the reports that let the agent do the tasks safely, at the scale of an entire portfolio.