

Search engines are no longer the only machines reading your site. Large language models now answer questions about your content, and they reward pages that are easy to parse. This is a practical guide to making WordPress content AI-ready with three lightweight tools: JSON-LD structured data, an llms.txt file, and FAQ schema — exactly how I rolled them out across many sites.
I run a portfolio of many WordPress sites — a tech blog plus several real-estate and classifieds platforms — and I wanted every one of them to be read correctly by both search engines and AI assistants. Making my sites AI-friendly and SEO-friendly at the same time is exactly what pushed me to roll out the three signals below; this post shares what I did and why.
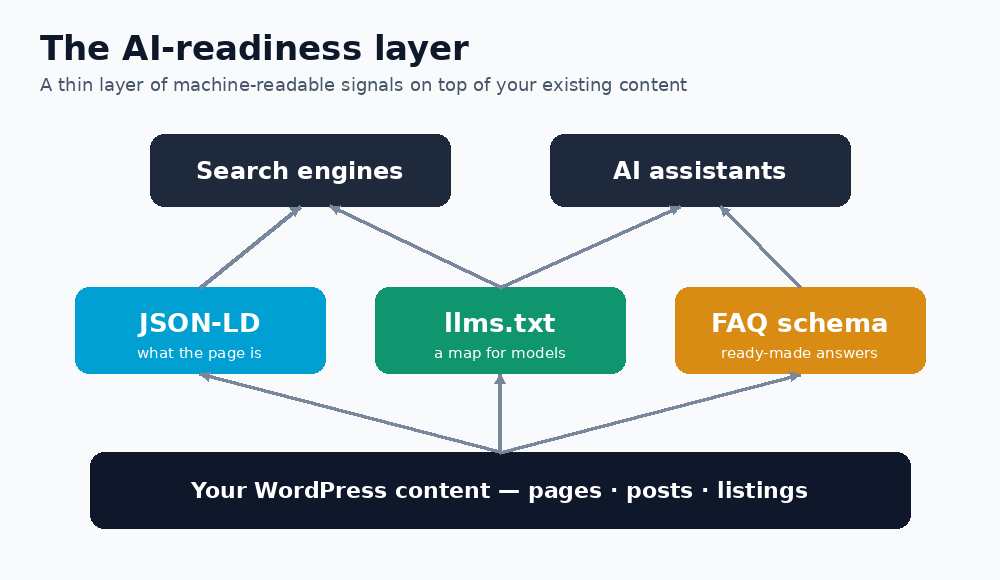
Why “AI-ready” is different from classic SEO
Classic SEO optimises for ranking. AI-readiness optimises for understanding: can a model reliably extract what your page is, what it offers, and the answers it contains — without scraping ambiguous HTML? Structured, machine-readable signals do that job, and they happen to help traditional search too.
1. JSON-LD: tell machines what the page is
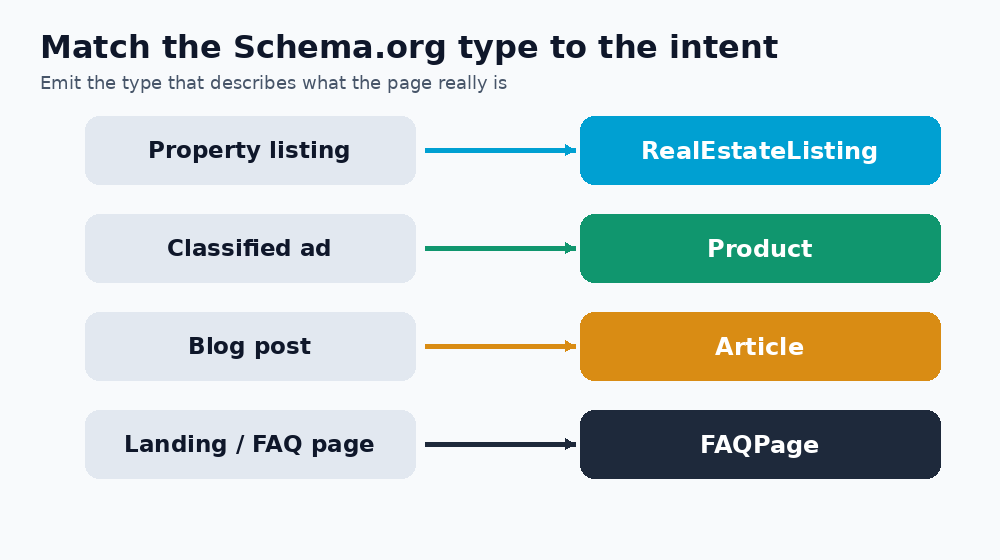
JSON-LD is a small block of structured data describing the entity on the page. A property listing becomes a RealEstateListing with a price, currency and address; a blog post becomes an Article with a section and keywords; a landing page can carry a FAQPage.
My advice: generate it dynamically from live data rather than pasting static blocks. If your SEO plugin already emits a schema graph, hook into it and add domain-specific pieces instead of shipping a competing block — you avoid duplicates and inherit clean identifiers.
- Be accurate: emit only fields you can trust. A wrong, duplicated value is worse than an absent one.
- Match the type to the intent: classifieds map to
Product, properties toRealEstateListing, editorial toArticle. - Keep currency explicit: prices without a currency code are ambiguous to a machine.
2. llms.txt: a plain-text map for language models
The llms.txt convention is a Markdown file at your site root that introduces the site and lists its key pages, articles and listings with short summaries. Think of it as a friendly, curated sitemap written for models rather than crawlers.
Two things make it effective: a one-line intro that states what the site is and who it serves, and concise summaries (reusing your meta descriptions works well). Serve it dynamically so it stays fresh as you publish, and cache it to keep it cheap.
3. FAQ schema: answers models can lift directly
An FAQPage block turns a list of question-and-answer pairs into structured data. Models — and search engines — can surface those answers directly. The trick is to keep the source editorial: store the questions and answers as data, render them as schema, and write them for real human queries (“How do I rent in this city?”, “What documents do I need?”).
Across my real-estate sites, a home-page FAQ of nine to eleven localised questions covers the most common buyer and renter intents and gives assistants something concrete to quote.
Putting it together without breaking your site
Ship these as additive, isolated pieces: each behind its own on/off switch, each defensive enough that a failure returns the page unchanged instead of erroring. Treat structured data like code — verify it on live pages, and prefer removing a signal over emitting a wrong one.
FAQ
Is JSON-LD a Google ranking factor?
It is not a direct ranking boost for every type, but it makes your content eligible for richer treatment and far easier for any machine — search or LLM — to interpret correctly.
Do I need llms.txt if I already have a sitemap?
They serve different readers. A sitemap lists URLs for crawlers; llms.txt curates and summarises the important content in plain language for models.
Where do FAQ answers come from?
Write them editorially for genuine user questions, store them as data, and emit them as FAQ schema. Keep them factual and concise — one to three sentences each.
AI-readiness is not a rewrite of your site; it is a thin layer of honest, machine-readable signals on top of content you already have. Add JSON-LD, publish an llms.txt, answer real questions with FAQ schema — and let the machines read you correctly.